作者:Dan Shipper,Every CEO;编译:Peggy,BlockBeats
近期,关于AI替代白领工作的讨论甚嚣尘上。从代码生成到客服自动化,AI智能体(Agent)似乎正在接管越来越多知识工作。各类基准测试也在加剧这种焦虑:模型在研究生级推理、真实经济任务和高级代码重构中的表现快速攀升,仿佛一个“人类工作被全面自动化”的临界点近在眼前。
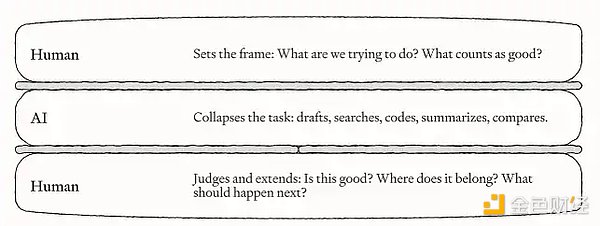
然而,深度使用AI的Every公司CEO Dan Shipper却提出了一个相反的观察:自动化程度越高,人类需要完成的工作反而越多。Every内部已将Codex、Claude Code、Slack Agent、客服Agent等工具深度嵌入工作流程,但结果并非员工被替代,而是工作形态发生了根本性重组。
工程师不再只是写代码,而是转向审查、重构和设计系统;编辑不再仅负责写稿,而是判断什么值得写、如何写出差异化;客服人员不再处理每张基础工单,而是维护能自动响应的系统。AI擅长将已沉淀的能力商品化——代码、文案、设计、报告均可快速生成。但当这些能力变得廉价,市场上涌现的往往是大量相似、缺乏语境判断的“默认输出”。
换言之,AI商品化的是“昨天的人类能力”,而真正稀缺的,是面对当下具体问题时的判断力。自动化没有消灭专家,反而创造了更多需要专家介入的场景:当运营人员用AI提交代码,就需要工程师判断哪些值得合并;当市场人员秒生成缩略图,就需要设计师判断何为符合品牌;当工程师也能写文章,就需要编辑将初稿转化为有观点、可发布的内容。
作者用基准测试解释了这一悖论。无论是高级工程师基准测试还是OpenAI的GDPval,模型得分衡量的都不是抽象“智能”,而是在特定问题框架内的表现。Prompt、任务边界、评价标准都已包含大量人类判断。模型可以在框架内快速爬坡,但框架本身由人设定;当一个框架被攻克,人类又会将问题推进到更复杂的新框架中。
文章对AGI焦虑给出了独特回应:即便模型越来越强,它追上的往往是人类画出的某条边界,而非画出边界的人。AI可以执行目标、优化路径,但只要它仍在回应人类设定的问题,就缺乏真正的主体性。知识工作的未来,并非人类从流程中消失,而是从执行者转向框架设计者、系统维护者、质量判断者和意义定义者。
自动化之后,人类工作的价值并未消失,而是变得更难、更靠前、也更依赖判断。AI让“会做”变得便宜,却让“知道什么值得做、为何做、做到何种程度才算好”变得更为稀缺。
实践中,Every公司的工作方式正演变为两种模式:一是将Agent视为“员工”,委派其完成特定任务;二是人类与Agent在如Codex、Claude Code等“工作操作系统”中实时协同。两种模式均需人类深度参与——设定方向、检查质量、转化决策。
AI让过去稀缺的能力变得充裕,但充裕导致同质化,同质化则激发对差异化的新需求,而这本质上是对人类专家判断的新需求。模型基于“过去”训练,而人类活在“当下”,带着不断变化的欲望、关切与判断去理解何为重要。
因此,即便基准测试分数指数级增长,其衡量的仍是框架内的表现。当模型攻克一个框架(如“重写代码库”),该能力便变得廉价,随之激发出海量应用需求。而这些新产生的、具体情境下的工作,又需要专家来判断、筛选与提升,从而催生更复杂的框架。循环由此不断重复。
文章最后借用一个寓言反思:一个愚笨之人通过笔记找到了所有衣物,却惊恐地问:“现在,我自己在哪里?” 在AI时代,我们或许也面临相似的追问:当AI高效地执行了我们设定的所有框架,那定义框架、赋予意义、活在具体情境中的“我们”,究竟在哪里?答案或许是——我们正退后一步,成为那个更不可或缺的“框定者”。