过去一年,业界对DeepSeek的讨论多集中于其模型性能、开源策略与定价。然而,若仅从应用层变现的角度审视它,或许低估了其更深远的野心。一种观点认为,DeepSeek的战略核心并非短期售卖API或订阅服务,而是通过颠覆性的底层技术创新,重塑AI计算的成本结构,并以此培育一个庞大的替代性硬件生态体系。
从MoE(专家混合模型)、MLA(多头潜在注意力)到DSA(解码器敏感注意力)、CSA(压缩滑动注意力),再到mHC(流形约束超连接)和Engram(记忆印迹),DeepSeek的技术演进始终围绕一个核心命题:在高端HBM内存、先进制程芯片、先进封装及CUDA生态受限的背景下,如何用更少的顶级算力训练和运行更强大的模型。

其创新的直接效果是显著降低了对稀缺且昂贵的硬件资源的依赖。以关键的KV Cache(键值缓存)为例,在100万上下文长度的极端场景下,DeepSeek V4 Pro仅需约5.48GB的HBM(高带宽内存),而同期其他主流大模型的需求高达60GB至89GB。这种数量级的压缩,使得将KV Cache卸载至SSD(固态硬盘)并长时间保留成为经济可行的方案,从而降低了对HBM的强依赖。
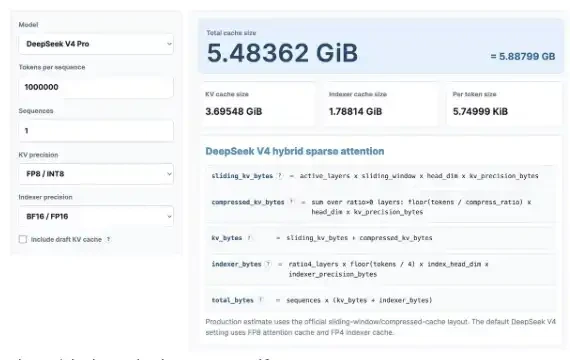
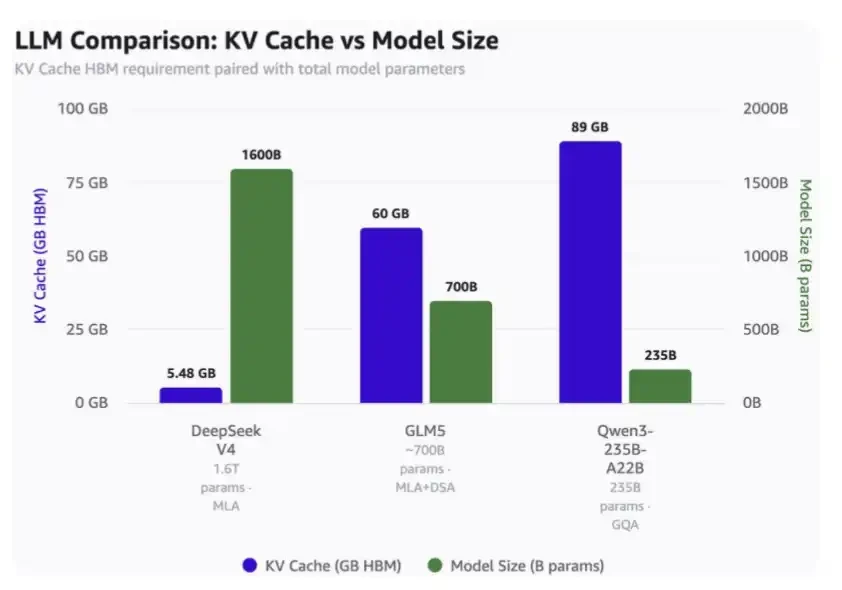
这一技术路径恰好与中国硬件产业的供给能力形成互补。HBM是目前中国半导体产业的短板,但中国在NAND闪存(如长江存储)和LPDDR内存(如长鑫存储)领域已具备相当产能和技术储备。DeepSeek的架构使NAND SSD能够高效承接海量KV缓存,而LPDDR则可用于模型的权重流式加载或存储Engram所需的嵌入表,实现“以内存换计算”的性价比优化。
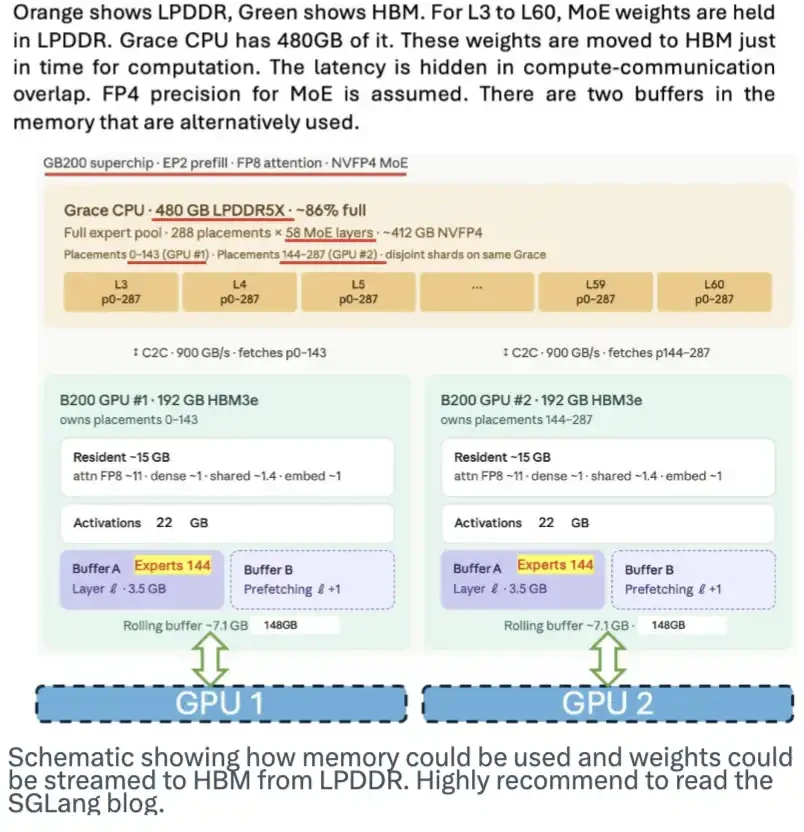
此外,DeepSeek对TileLang等编程语言的投入,意在构建一个跨硬件平台的统一编译层,从而削弱现有CUDA生态的垄断性壁垒,为国产GPU、ASIC等算力芯片提供更友好的软件入口。

文章指出,DeepSeek的长期目标可能不是直接从模型服务中赚取数十亿美元,而是通过赋能整个硬件生态,分享更庞大的价值。其商业模式可参照OpenAI与AMD的合作模式:通过大规模采购承诺与深度技术协作,换取硬件厂商的股权或收益权。随着其开创的算法标准被广泛采纳,一个由国产存储、算力芯片、网络设备构成的AI基础设施链条有望崛起,其潜在市场规模被预估可达十万亿美元级别。而作为关键推动者和标准制定者,DeepSeek在其中有望实现自身价值的极大化。
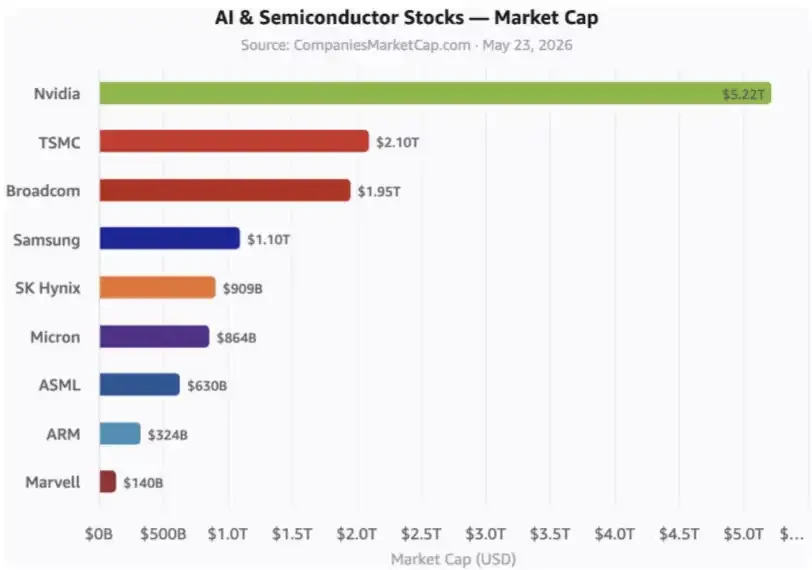
当然,这一判断带有较强的推演色彩。DeepSeek能否真正引领生态、其技术红利如何具体转化为商业回报,仍需时间验证。但可以确定的是,其开源与低价策略并非简单的市场竞争手段,而是服务于重塑产业底层规则、解锁更广泛AI普及能力的宏大战略。DeepSeek最终出售的,可能不是模型本身,而是下一代低成本、高性能AI基础设施的“可行性”。