六周。这就是 Anthropic 从 Opus 4.7 到 Opus 4.8 所需的时间。
新模型在基准测试中更快、更智能,并配备了一系列新功能,但价格没有变化:与以前相同,每百万个输入代币为 5 美元,每百万个输出代币为 25 美元。
还有一种快速模式,每百万美元的输入为 10 美元,输出高达 50 美元,以 2.5 倍的速度运行相同的模型。 Anthropic 表示,现在的费率比以前型号的快速模式成本便宜三倍,这是一个很好的方式来说明它以前要贵得多。
SWE-bench Pro 可能是最重要的基准测试,可以了解该模型的性能。它衡量人工智能是否能够真正解决来自真实生产代码库的多语言软件工程难题,以通过问题的百分比进行评分。
在该测试中,Opus 4.8 的准确率达到 69.2%,高于 Opus 4.7 的 64.3%。 OpenAI 的 GPT-5.5 得分为 58.6%,谷歌的 Gemini 3.1 Pro 以 54.2% 落后。对于相同价位的型号来说,这是一个有意义的跳跃。
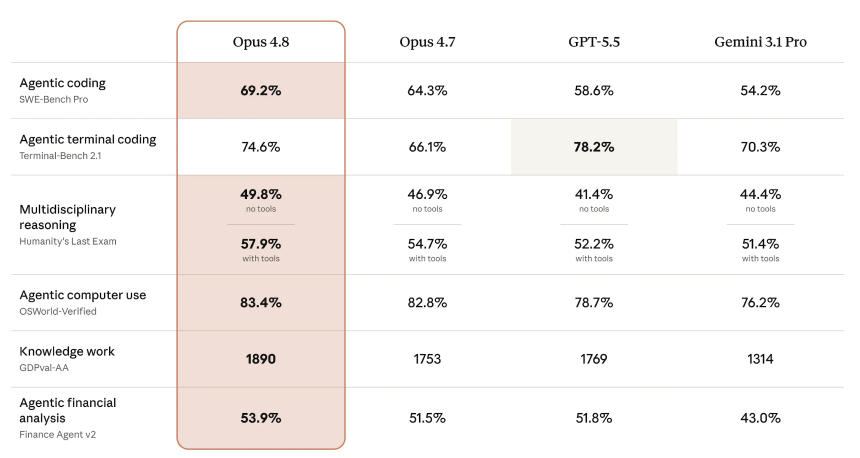
在 Humanity 的最后一次考试中(涵盖数十个学科的专家级问题,以正确百分比进行评分),Opus 4.8 在不使用工具的情况下达到了 49.8%,在使用工具的情况下达到了 57.9%,领先于所有三个竞争对手。 OSWorld-Verified 测试了现实世界中的计算机使用任务,例如导航软件 UI,得分为 83.4%,略高于 Opus 4.7 的 82.8%。
唯一的损失:Terminal-Bench 2.1,它测量命令行任务上的人工智能性能。 GPT-5.5 以 78.2% 的成绩领先,而 Opus 4.8 的成绩为 74.6%,优于 Opus 4.7 的 66.1%,领先于 Gemini 的 70.3%,但第二名最终仍将落败。
五种思考方式
Anthropic 现在允许用户控制模型思考的难度。 “High”是默认值,可以很好地处理大多数任务,而“Extra”(在 Claude Code 中称为“xhigh”)则需要花费更多的计算来解决更困难的问题。 “Max”是最深处。 “低”和“中”为同一任务投入较少的令牌,节省一些时间以换取准确性。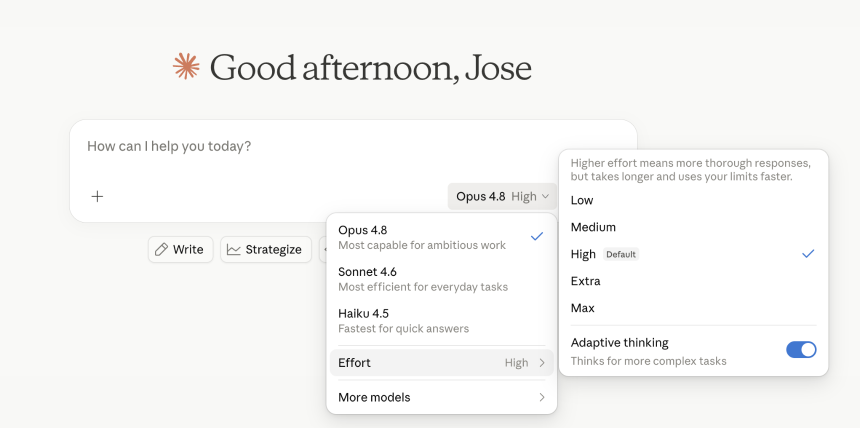
工作量控制位于 claude.ai 和 Cowork 中的模型选择器旁边,适用于所有计划。 Anthropic 表示,默认的 high 使用与 Opus 4.7 的默认标记大致相同的标记,但结果更好——这要么是令人印象深刻的工程设计,要么是良好的消息传递,或许两者兼而有之。
同样重要的是要记住,Anthropic 的 Opus 新标记器在每个任务中使用更多标记。因此,如果 Claude 用户选择 Opus 而不是 Claude Sonnet,那么他们不可避免地会花费更多的钱来完成任务。Claude Sonnet 是一种能力较差的模型,但对于日常任务和未达到前沿科学或编码水平的复杂问题来说可能足够好了。
克劳德代码中的速率限制也被提高,以吸收额外和最大设置产生的更高的代币支出。
几乎和 Claude Mythos 一样安全
Anthropic 的联盟团队表示,Opus 4.8“在我们的亲社会特征衡量指标上达到了新高,例如支持用户自主权和以用户最大利益行事。”更具体地说:欺骗率和误用合作率远低于 Opus 4.7,与 Claude Mythos Preview(Anthropic 最锁定的模型)相当。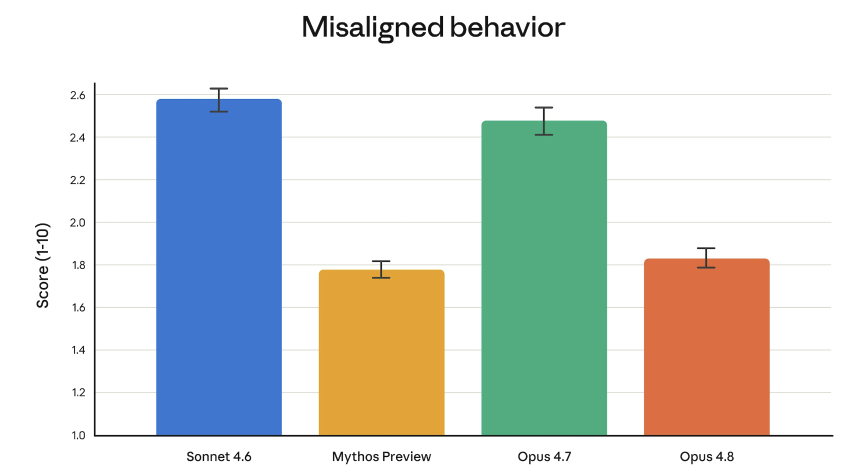
与 4.7 相比,Opus 4.8 让自身代码中的错误溜走而不标记它们的可能性要低四倍。
这种神话比较值得参考。 Mythos 完全高于 Opus,Anthropic 将其描述为“比我们的 Opus 模型更大、更智能”。目前它仅作为预览版存在,少数经过审查的组织可以通过Project Glasswing进行网络安全工作。
英国人工智能安全研究所发现,它可以自主完成“The Last Ones”,这是一个 32 步的企业网络攻击模拟,通常需要人类红队 20 个小时才能完成。这就是为什么它尚未出售。 Anthropic 表示,更强大的网络保护措施正在进行中,并预计“在未来几周内”将 Mythos 级模型带给每个人。
今天还将发布:Claude Code 中的动态工作流程,处于研究预览阶段。该功能允许 Claude 编写自己的编排脚本,并在单个会话中启动并行子代理,验证其输出并报告回来,就像 Hermes 一段时间以来所做的那样。
动态工作流程可供 Enterprise、Team 和 Max 计划用户使用,Anthropic 预先表示,它们比标准 Claude Code 会话消耗的代币要多得多。
价格差距扩大
Anthropic 的 5 美元/25 美元定价看起来与中国最近的做法截然不同。
DeepSeek V4 Pro 上周永久保留了 75% 的折扣:每百万个输入代币 0.435 美元,每百万个输出代币 0.87 美元。 Xiaomi MiMo V2.5 Pro 通过 OpenRouter 等提供商以相同的速率运行。
Anthropic 的快速模式每百万的输入成本为 10 美元,输出成本为 50 美元,比标准 Opus 4.8 本身更贵,每个输出令牌大约是 DeepSeek V4 Pro 的 57 倍。企业已经花费了数百万美元来推理美国模型。尽情使用 Opus,您的企业可能很快就会达到数百万美元。
Anthropic 对价格差距的回答是质量和安全。在 SWE-bench Pro 上,Opus 4.8 击败了这两款中国型号。在一致性方面,两者都没有接近 Anthropic 发布的基准。
这些事情在生产环境中很重要,在生产环境中,模型悄悄地与不良投入合作是一种实际风险——受监管的行业、法律工作以及任何“看起来不错”的事情都不是可接受的事后报告。对于其他人来说,这种差距很难忽视。
我们测试了
我们进行了快速编码测试,以创建 3D 僵尸游戏,看看 Claude Opus 4.8 如何与 ChatGPT 和 DeepSeek(可以说是来自美国和中国的最受欢迎的竞争对手)相比。我们将 Opus 4.8 设置为默认高,将 GPT-5.5 设置为高工作量,将 DeepSeek V4 Pro 设置为高工作量 — 三个模型,一个提示,不重试。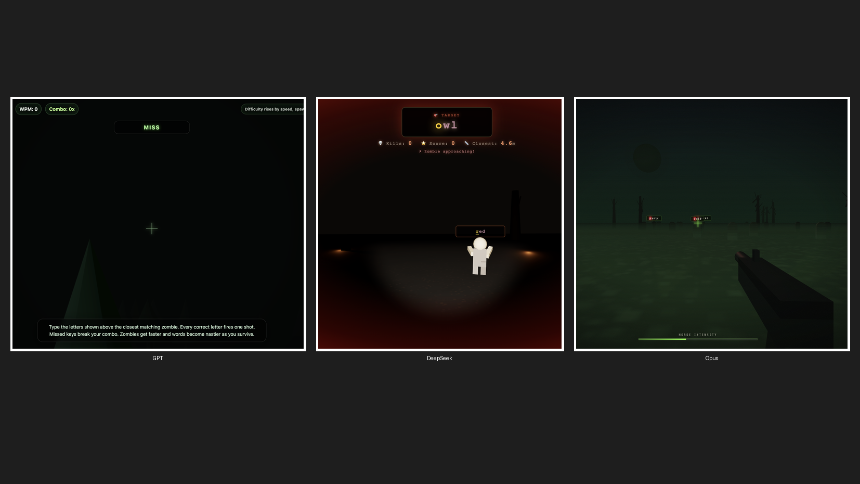
GPT-5.5 获得第一名。它的游戏没有僵尸视觉效果,也没有声音效果。当然,它很快,但它完全错过了简报。
DeepSeek V4 Pro 凭借鼠标移动、真实的僵尸角色、音效、坚实的机制和简洁的美感位居第二。没有抱怨。
Opus 4.8 的耗时大约是 GPT-5.5 的三倍,但提供了最好的启动画面、最好的僵尸设计、最好的游戏机制和不错的音效。这是最慢的,但输出最好。不过,考虑到成本差距,这可能不足以证明使用它优于 DeepSeek 的合理性。
所有游戏都可以在我们的 Itch.io 个人资料中找到。 GPT-5.5 生成了Zombie Typing,Opus 生成了Typing Dead,而 DeepSeek v4 Pro 生成了一款没有名称的游戏,可以让您直接进入操作。我们称之为 TypeSeek。
完整的比较审查即将到来。目前:对于此类任务,Claude Opus 4.8 的代码比 GPT-5.5 和 Opus 4.7 更好,而 Anthropic 自 4.7 以来收取的价格相同。已经为每百万代币支付 5 美元的开发者刚刚免费获得了更好的模型。