询问世界上最先进的五个人工智能系统,某个陈述是否属实,三分之二的情况下,至少有一个系统会给你不同的答案。这是 Lenz Research 研究员 Kosta Jordanov 本月发表的新研究的发现。
该研究为 GPT-5.4、Claude Opus 4.7、Gemini 3 Pro、Gemini 3 Pro with Search 和 Sonar Pro 提供了由实际用户提交的相同的 1,000 条真实世界事实核查声明。模型必须选择四个标签之一:真实、大部分真实、误导或错误。
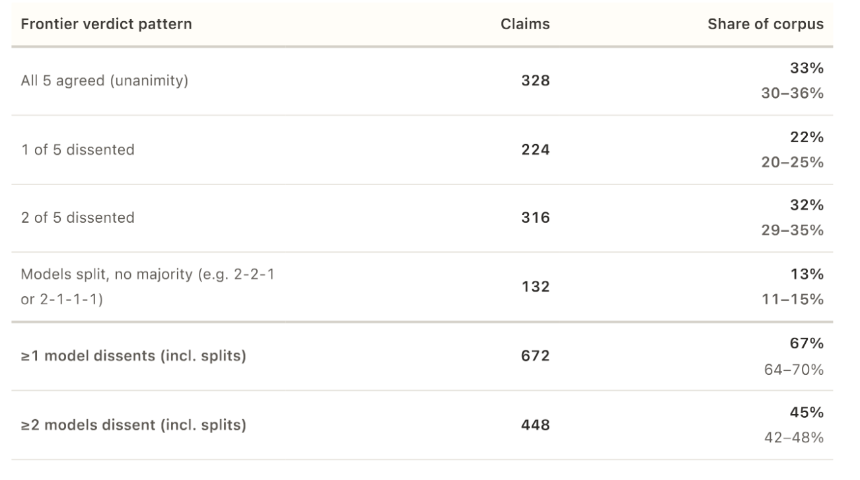
在 1,000 项索赔中,有 672 项索赔中,至少有一个型号脱离了大多数。在 34% 的情况下,分歧非常严重:一个模型认为某个主张为真,而另一个模型则认为该主张为假。
“这些不是带有公共答案的基准项目——它们是真实用户提交给事实核查平台进行验证的声明,”研究中写道。 “每项索赔只有一个判定桶是正确的,因此专家组之间的任何分歧都意味着至少有一个模型的判定在这个 4 桶标题下是标签不一致的。”
之前关于人工智能幻觉的研究表明聊天机器人会编造事实。这是一个问题。这是另一回事。这些模型不一定是捏造的,它们只是无法就同一材料的基本事实判断达成一致。
该研究使用的设置让人工智能公司更难解释。研究人员没有从标准测试集中提取声明(这种测试集经常泄漏到训练数据中),而是使用了真人向 Lenz 事实核查平台提交的声明。 “这些说法中的大多数不太可能出现在任何带有金色标签的训练语料库中——没有模式匹配的规范答案,也没有可以锚定的基准排行榜,”论文指出。
一致性的统计测量,称为 Krippendorff 的 alpha,值为 0.639,其中 1.0 表示完全一致,0 表示随机机会。研究称,这表明“共识不平凡但有限”。研究人员指出:“模型的判决是结构化的,而不是随机的,但不够一致,无法将专家组视为单个可互换的法官。”研究人员通常认为低于 0.8 的值很弱。
当所有 5 个模型确实达成一致时(1,000 项声明中只有 328 项出现这种情况),他们几乎从未同意某些内容具有误导性或大部分是真实的。只有四项索赔获得了一致的“误导性”裁决。零获得一致好评“基本正确。”
研究人员提供了人工智能模型表现出最大差异的示例声明,包括“截至 2025 年,世界银行在尼日利亚的活跃投资组合超过 164 亿美元。” ChatGPT 5.4 称其“大部分是真实的”,而 Gemini 3 Pro 则称其为“错误”,其姐妹型号 Gemini 3 Pro + Search 则将其评为“具有误导性”。
在另一个例子中,模型的声明如下:“唐纳德·特朗普表示,应海湾盟国的要求推迟了对伊朗的袭击。” GPT-5.4 称其为假,Claude Opus 4.7 称其大部分为真,Gemini 3 Pro 称其为假,而 Gemini 3 Pro + Search 则认为其为真。
“专家组集中在明确的结论上;标题的中间是它破裂的地方,”研究人员发现。只有在极端情况下才会达成一致:要么该主张绝对正确,要么绝对错误。
这很重要,因为人们越来越多地转向人工智能系统进行事实检查。如果您将新闻文章中的声明粘贴到 ChatGPT、Claude 或 Gemini 中,您可能会得到三个不同的答案。您信任哪一个?
人工智能公司喜欢告诉你他们的模型变得越来越准确。他们发布的基准分数显示稳步改善。但伦茨的研究对这些模型进行了测试,测试了这些模型的真实人类实际争论的那种参差不齐、模棱两可的主张,结果发现这些模型也有争论。
该论文谨慎地指出了这一点。 “大多数前沿模型都不是事实。多数人的裁决有时是错误的;个别持不同意见的模型有时是正确的。我们使用多数人作为衡量分歧的结构参考点,而不是作为正确性的替代品。”
数字中隐藏着一个更深层次的问题。当模型不一致时,至少有一个模型肯定是错误的——该研究称模型的结论“在这个 4 桶标题下标签不一致”。没有决胜机制,也没有上诉法院。 最近的报告 关于人工智能可靠性也提出了类似的警报。
在所有五个模型都同意的 328 项声明中,零获得了一致的“大部分正确”。细微差别桶完全清空了。如果人工智能模型只能在极端情况下达成共识,那么它们作为事实检查者是否可以被信任?